
MemHC improves the efficiency of complex supercomputer physics calculations by optimizing memory management.
September 20, 2023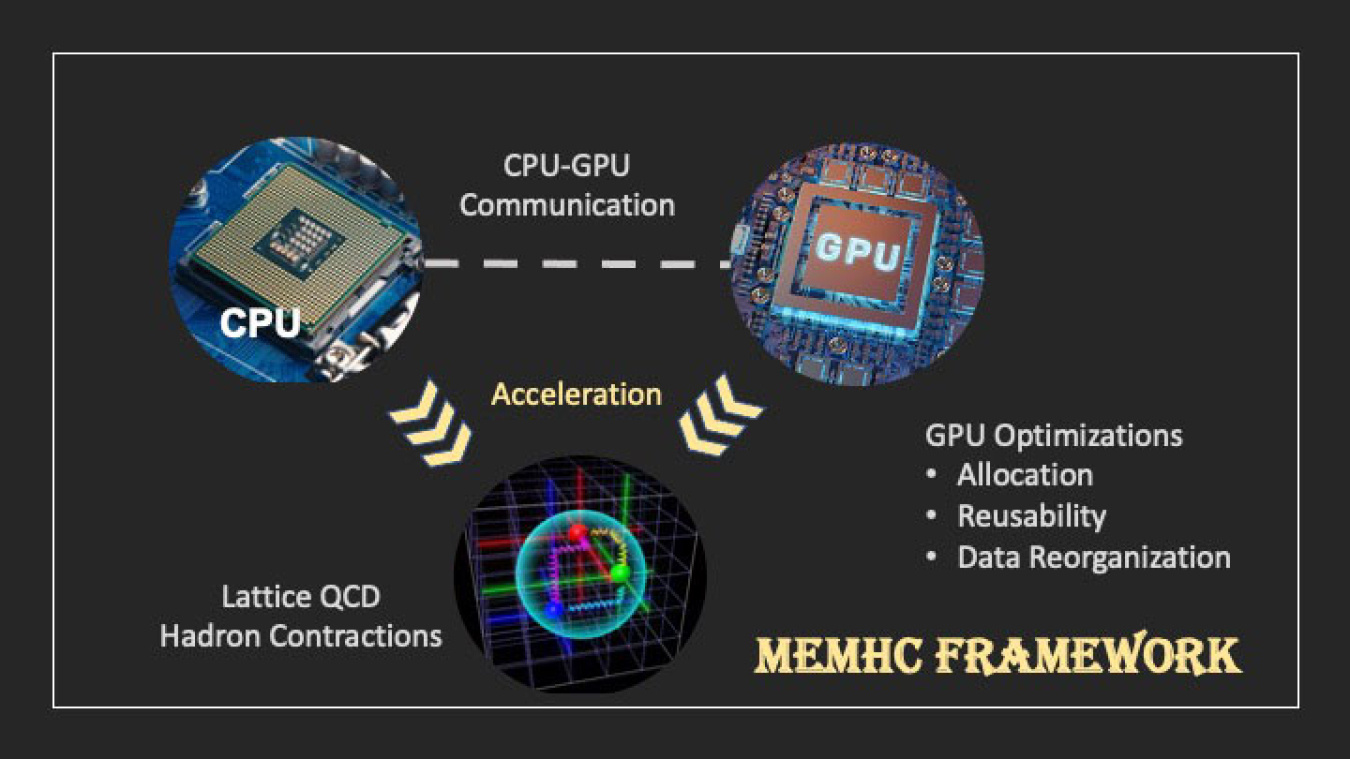
The Science
Quantum chromodynamics (QCD) is the theory that describes the internal structures of protons and neutrons. One approach to applying QCD to research involves a type of complicated calculation that only a supercomputer can handle. However, these calculations are so demanding they can even slow down a supercomputer. Researchers sped up a test computer’s calculations by more than 300% by employing a novel framework that manages how and when the computer uses memory. The MemHC framework reduces the amount of information the computer transfers between its internal components. It eliminates unnecessary crosstalk—noise caused by signals that interfere with each other—between processing units. Finally, it also allows some completed calculations to remain in memory to be reused as needed.
The Impact
MemHC improved the test computer’s calculation speed, resulting in quicker results. This performance boost opens the door to more complex calculations than previously possible. It also clears the way for similarly difficult calculations to be completed faster. This would allow nuclear physicists to accomplish more of these types of calculations within their allotted supercomputer research time. The more supercomputer clusters that use MemHC, the faster physicists can complete calculations of QCD. The ultimate result will be better scientific understanding of the properties of protons and neutrons.
Summary
Computers help physicists solve complicated calculations, but some advanced problems tax even the largest supercomputers. Scientists at the Thomas Jefferson National Accelerator Facility (Jefferson Lab) and William & Mary have developed MemHC, a new tool to speed up these calculations. MemHC organizes the memory of a common component of many supercomputers, the graphics processing unit (GPU). In a gamer’s computer, GPUs quicken the rendering of graphics for smoother play. They do the same for complicated calculations in supercomputers. But GPUs operate with limited memory, so these supercomputers must pass information frequently from the GPU to and from its host, the central processing unit (CPU), leading to a loss of efficiency.
MemHC uses three memory management methods to reduce redundancy. Many problems include repetitive calculations, so MemHC keeps certain calculations on the GPU to be reused as needed. The GPU only needs to communicate the result to the CPU, not the intermediate computational steps, so MemHC removes the unnecessary intermediate communication. Finally, MemHC optimally moves data from the CPU onto the GPU only when needed. In this work, MemHC was outfitted for a single GPU and CPU. It resulted in 2.17 to 10.73 times more gigaFLOPS of compute power. The researchers are now extending this framework to multiple GPUs.
Contact
Robert Edwards
Thomas Jefferson National Accelerator Facility
edwards@jlab.org
Funding
This work was funded by the Department of Energy Office of Science, Office of Nuclear Physics and William & Mary.
Publications
Wang, Q., et al., MemHC: An Optimized GPU Memory Management Framework for Accelerating Many-body Correlation.ACM Transactions on Architecture and Code Optimization 19, 1 (2022). [DOI: 10.1145/3506705]
Related Links
Reducing Redundancy to Accelerate Complicated Computations, Jefferson Lab feature story